 INTRODUCTION
INTRODUCTION
Qu’est ce que le C++ ?
C’est avant tout un langage de programmation, orienté objet, aux normes ANSI et ISO.
Orienté objet ? Cela signifie quoi au juste ?
Il faut savoir une chose relativement importante à propos du C++. Il est de bas niveau, ce qui fait de lui, un langage de création de programme très efficace et très rapide.
Le C++ supporte des méthodes de programmation qui simplifient la création d’application qui est évolutive à l’infini.
Les différentes normes qui lui sont attribuées, lui permettent d’avoir une garantie sur la possibilité de portabilité.
Compactibilités avec les différents environnements de son utilisation ?
Les programmes C++ sont compatibles avec quasiment tous les environnements de développement modernes.
CONSEILS, RECOMMANDATIONS et la LEGENDE
1) Faire un bon programme, en ce posant les bonnes questions :
Qu’est qu’il y a faire ?
Création d’un algorithme (esquisse sur papier du code).
Analyse des différents points d’algorithme.
Codage puis compilation.
2) Clarifier le code source par des commentaires.
Un bon conseil de programmeur et de développeur, n’hésitez pas à mettre des commentaire dans vos codes sources. Pourquoi ???
Car, cela est plus facile et plus rapide à comprendre pour toutes les autres personnes non - développeurs, développeuses. De plus, ce sont des explications qui argumentent pourquoi vous avez écrit ce bout de code.
Pour cela, vous avez à votre disposition, la double barre (//), ou tous les caractères y sont autorisé.
De même, pour ignorer un bout de programme, on le transforme sous la forme d’un commentaire en utilisant les signes (/* */). Ce qui implique que ce bout de code placé entre ces deux symboles sera totalement ignoré.
3) Essayer, de retenir tous ce que j’ai mis en rouge. De plus, ce qui est surligné en
vert apporte un petit plus, un conseil, et parfois la réponse au problème. Pour en
finir avec tout cela, ce qui en jaune, c’est avant de vous montrez ce qui peut être aussi à savoir (mais surtout à bien comprendre).
4) Parfois, je pus faire des petits commentaires personnels (par exemple entre (! !)), c’est à prendre au second degré. De plus, j’ai rajouter des liens vers les TP’s correspondant à chaque chapitre. Vous pouvez retrouver les differents liens en annexe dernier page.
BON COURAGE……
DECLARER DES VARIABLES
Une déclaration est une instruction qui définit une variable.
Une variable est un « récipient » qui renferme une valeur d’un certain type. Il est de rigueur que le nom d’une variable commence par une minuscule, et que chaque nouvel élément de nom commence par une majuscule.
Attention :
- Efforcez-vous de donner à vos variables des noms brefs et évocateurs.
- Evitez un nom comme x car cela signifie rien.
- Un nom de variable doit le plus explicite avant tout.
! Malgré, nos ordinateurs très puissant, il n’en reste pas moins débile pour autant. ! Enfin, avant d’utiliser une variable, il faut obligatoirement la définir, pour dire à l’ordinateur à quoi correspondent cette variable et son type.
Il vous cependant possible de déclarer des variables partout dans votre programme, du moment qu’elles sont définies avant d’être utilisées.
Voici un petit tableau représentant les différents types de variable disponible, leur représentation en C++ et la place qu’ils prennent en mémoire.
| Type | Représentation C++ | Taille en bits | Valeurs limites |
| Entier court Entier Entier long | short int long | 16 16 – (32) 32 | -32768 à 32767 -2 147 483 648 à +2 147 483 647 -2 147 483 648 à +2 147 483 647 |
| Entier court non signé Entier non signé Entier long non signé | unsigned short unsigned int unsigned long | 16 16 – (32) 32 | 0 à +65535 0 à +4 294 967 295 0 à +4 294 967 295 |
| Réel Réel en double précision Réel en très grande précision | float double long double | 32 64 80 | ± 10 -37 à ± 10 +38 ± 10 -307 à ± 10 +308 ± 10 -4932 à ± 10 +4932 |
| Caractère Caractère non signé | char unsigned char | 8 8 | -128 à 127 0 à 255 |
| Booléen | bool | 1 | false ou true (faux ou vrai) |
Voyons voir maintenant quelles sont les constantes littérales :
| Type | Description |
| Entière | Les constantes littérales entières peuvent écrites en notation décimale, octale ou hexadécimale : • 20 // décimal • 024 // octal (Ajouter un 0 à une constante littérale entière conduit à interpréter cette constante en octal) • 0x1F // hexadécimal (Ajouter 0x aura comme conséquence une interprétation en hexadécimal) Il existe aussi des suffixes pour donner d'autres précisions • 128L // constante littérale entière de type long • 24U // constante littérale entière non signée • 8LU // constante littérale entière de type long et non signée |
| Réelle | Une constante littérale réelle peut être écrite en notation scientifique ou en notation décimale courante. Avec la notation scientifique, l'exposant peut être écrit avec E ou e. Par défaut, les constantes littérales réelles sont traitées comme des types double. Pour traiter les différents types réels, on utilise également des suffixes. • 15.3 // constante littérale réelle de type double en notation décimale courante • 1.53e+1 // constante littérale réelle de type double en notation scientifique • 3.1415F // constante littérale réelle de type float (simple précision) • 12.345L // constante littérale réelle de type long double (précision étendue) |
| Caractère | Un caractère littéral affichable constant peut être écrit en entourant ce caractère avec des apostrophes. • ‘a' ..... ‘2'.....‘,' ..... ‘ ‘ (espace) Certains caractères non affichables comme les caractères de contrôle peuvent être représentés par les séquences d'échappement suivantes : • \n // nouvelle ligne • \t // tabulation horizontale • \v // tabulation verticale • \b // retour arrière • \r // retour chariot • \f // saut de page • \a // alerte (cloche) • \\ // barre oblique inverse • \' // apostrophe • \“ // guillemet Une séquence d'échappement peut être suivi d'un nombre. Ce nombre correspond alors au code ASCII qui représente le caractère : • \7 (cloche) --- \13 (nouvelle ligne) --- \0x0C (nouvelle ligne) --- \65 (‘A') --- \0x41 (‘A') --- \0 (nul) |
| Booléenne | Il n'existe que deux littéraux vrai ou faux : true, false. |
Remarque : Dans un programme, il peut arriver que l'on ait besoin de manipuler des entités qui demeurent constantes. Il existe un mot réservé dans le langage C++ qui manipule ces entités, il s'agit de « const ». La syntaxe à utiliser est la même que pour les variables, il suffit de rajouter le préfixe const.
a) Peut on déclarer une variable sans la définir ?
En C++, cela est possible. Il faut utiliser le préfixe « extern ».
Par exemple, dans un programme, nous avons quelque fois besoin d'une variable globale. Un problème se pose si notre programme est décomposé en plusieurs fichiers. En effet, nous savons que nous devons définir cette variable qu'une seule fois, sinon, nous avons une duplication de nom sur la même portée. Sa définition va donc, nécessairement, se trouver dans un des fichiers.
Malheureusement, lorsque nous nous trouvons dans un autre fichier, le nom de cette variable n'est plus visible. Pour que le compilateur ne soit pas perturbé, il faut alors préciser que la variable est déjà définie mais à l'extérieur de notre fichier.
Si plusieurs fichiers sont concernés par ce problème, il est alors préférablede réaliser la déclaration au sein d'un fichier en-tête ce qui permet de l'écrirequ'une seule fois.
b) Explication supplémentaire sur les variables globale ou locale ?
Déclarer en local les variables propres à une fonction vous fait d'abord économiser énormément de mémoire, puisque la même zone (la pile) est utilisée pour créer les variables locales de toutes les fonctions, en sachant, qu'à un instant donné, seules quelques variables existent.
Dans le cas contraire, chaque variable devrait posséder sa propre case se qui représenterait une taille plus que conséquente.
Mais surtout, en utilisant des variables locales, vous rendez lesprogrammes plus lisibles et plus fiables en associant intimement les variables à leurs fonctions.
b1) Fiables ?
Parce que vous évitez ainsi qu'une variable utilisée dans une fonction ne soit malencontreusement modifiée par une autre fonction. En effet, une variableglobale est publique. N'importe qui peut l'atteindre. Nous risquons donc de retrouver cette variable dans un état qui n'est pas prévu au moment où nous en avons besoin.
Cette notion de protection est fondamentale et, dans la mesure du possible, il est préférable de ne jamais utiliser de variable globale.
Malgré toutes ces remarques, une variable globale possède l'avantage de proposer la persistance. Sa durée de vie est la durée de vie du programme.
Ainsi, il est possible de conserver une valeur indépendamment de la durée de vie de la fonction. Ce qui est dommage, c'est qu'elle soit publique.
c) Explication supplémentaire sur les variables statiques ?
Heureusement, le langage C++ propose les variables statiques qui permettent de gérer la persistance tout en ayant un statut privé. Une variable statique est une variable locale à une fonction, mais qui garde sa valeur d'une exécution à l'autre de la fonction.
Elle est introduite par le préfixe « static ». Du coup, cette variable utilise la zone d'allocation statique au lieu d'utiliser la pile. Bien que sa valeur persiste au cours des invocations de la fonction, la visibilité de son nom reste limitée à sa portée locale.

Comme la zone d'allocation est la zone statique, cette variable est systématiquement initialisée, soit par une valeur que vous devez préciser, soit automatiquement avec la valeur 0. Cette initialisation s'effectue uniquement lorsque l'exécution du programme passe sur la déclaration la première fois.
GESTIONS D’ E/S
Les entrées-sorties, c'est à dire les opérations de lecture à partir du clavier, d'un fichier disque ou d'un périphérique, et les écritures à l'écran, sur disque, imprimante ou périphérique, sont parmi les opérations les plus fréquentes sur ordinateur. La bibliothèque « iostream » fournie, entre autre, trois objets qui représentent les flots standard.
L'objet qui représente le flot standard doit impérativement être écrit en premier, suivi du symbole de redirection « >> » ou « << » (appelé doubles chevrons), suivi ensuite, soit de constantes littérales, soit de variables qui peuvent être de n'importe quel type prédéfini. Il est possible d'enchaîner plusieurs symboles de redirection entre les variables ou les constantes littérales.
Remarque : Le symbole de redirection indique le sens du transfert de  l'information. Dans le cas d'un périphérique d'entrée, il faut prendre « >> », dans le cas d'un périphérique de sortie, il faut prendre « << ».
l'information. Dans le cas d'un périphérique d'entrée, il faut prendre « >> », dans le cas d'un périphérique de sortie, il faut prendre « << ».
| #include | |
cin | Représente l'entrée standard. En général, cin permet de lire les données depuis le terminal de l'ordinateur. Sauf réglage contraire, il s'agit donc du clavier. cin >> x ; // Clavier ==> Variable x L'opérateur de redirection « >> » sert à assurer le transfert de l'information issue du clavier de l'ordinateur vers la variable x. Le sens de lecture va donc de la gauche vers la droite. La variable x peut-être ne n'importe quel type prédéfini, par contre, il n'est pas possible de placer à cet endroit une constante littérale. |
cout | Représente la sortie standard. En général, cout permet d'écrire des données pour le terminal de l'ordinateur. Sauf réglage contraire, il s'agit donc de l'écran. cout << x ; // Ecran ==> Variable x L'opérateur de redirection « << » sert à assurer le transfert de l'information issue de la variable x vers l'écran de l'ordinateur. Le sens de lecture va donc de la droite vers la gauche. La variable x peut-être de n'importe quel type prédéfini. Il est possible d'enchaîner plusieurs opérateurs de redirections. cout << « La valeur de x est : » << x ; |
cerr | Représente les erreurs standard. Là aussi, c'est généralement l'écran qui est utilisé, et la syntaxe est identique à cout. cerr << « erreur de transmission » ; |
Comment effectuer des opérations mathématique ?
En réalité c’est vraiment très simple à comprendre. Pourquoi ??? Car, les opérations en C++ ressemblent à celles que vous feriez avec un crayon et du papier, sauf qu’en l’occurrence, les variables doivent être déclarées avant de pouvoir être utilisées, comme nous le disions précédemment.
1) Notions d’arithmétique binaire :
Un opérateur binaire a deux arguments. Les opérateurs binaires les plus courants sont les opérations élémentaires.
Opérateurs de bit | Opération effectuée |
& | ET bit à bit |
^ | OU exclusif bit à bit |
| | OU bit à bit |
variable << décalage | Décalage à gauche |
variable >> décalage | Décalage à droite |
~ | Complément (NON) bit à bit |
2) Autres opérations arithmétiques :
Opérateurs relationnels | Opération effectuée |
> | Supérieur à |
>= | Supérieur ou égal à |
< | Inférieur à |
<= | Inférieur ou égal à |
== | Egal à |
!= | Différent de, ou non égal à |
&& | ET logique |
|| | OU logique |
! | NON logique |
Opérateurs arithmétiques | Opération effectuée |
+ | Addition |
- | Soustraction |
* | Multiplication |
/ | Division |
% | Modulo (reste d'une division entière) |
3) Opération d’incrémentation et de décrémentation :
-> Les affectations les plus fréquentes sont du type : i = i+1 ; ou i = i-1 ;. En C++, nous disposons de deux opérateurs supplémentaires pour ces affectations :
i++ | ++i | Pour l'incrémentation (augmentation de une unité) |
i-- | --i | Pour la décrémentation (diminution de une unité) |
4) Priorité des opérateurs
Priorité | Opérateurs |
1 (la plus forte) | ( ) [ ] -> . :: |
2 | ! ~ ++ -- (casting) * & new delete |
3 | * / % |
4 | + - |
5 | << >> |
6 | < <= > >= |
7 | == != |
8 | & |
9 | ^ |
10 | | |
11 | && |
12 | || |
13 | ? : |
14 (la plus faible) | = += -= *= /= %= …. |
Attention :
Dans chaque classe de priorité, les opérateurs ont la même priorité. Si nous avons une suite d'opérateurs binaires de la même classe, l'évaluation se fait en passant de la gauche vers la droite dans l'expression. Pour les opérateurs unaires (!,++,--) et pour les opérateurs d'affectation (=, +=, -=, *=, /=, %=), l'évaluation se fait de droite à gauche dans l'expression.
Dans chaque classe de priorité, les opérateurs ont la même priorité. Si nous avons une suite d'opérateurs binaires de la même classe, l'évaluation se fait en passant de la gauche vers la droite dans l'expression. Pour les opérateurs unaires (!,++,--) et pour les opérateurs d'affectation (=, +=, -=, *=, /=, %=), l'évaluation se fait de droite à gauche dans l'expression.
Nous pouvons forcer la priorité, en mettant des parenthèses, si elles ne changent rien à la priorité. Dans le cas de parenthèses imbriquées, l’évaluation se fait de l’intérieur vers l’extérieur.
Comment créer différentes boucles (for, while(){…}, do{…}while()) ?
| ALGORITHME | C++ | FONCTIONS |
| Tant que cVfaire Action 1 … Action N Finfaire | While(cV) { Action 1 ; Action N ; } | C’est une boucle avec un test au début. Il faut la cV sont vrai, pour pouvoir entrée dans la boucle. La sortie de la boucle sera effectué si et seulement si la cV est fausse. Rq : La boucle peut ne jamais être exécutée. |
| Pour id de debut à fin faire Action 1 .... Action N | 1ére passage, on initialise id a début. A chaque début de boucle on effectue le test suivant : id < fin. Si test =faux, on effectue le traitement interne a la boucle. Si test=vrai, on quitte la boucle. En fin de boucle, id est incrémente automatique de 1 avant le retour en début de boucle. Rq : id nous sert uniquement de compteur. | |
| Répéter Action 1 ..... Action N Jusqu'à (CV) | Do { Action 1 ; ….. Action N ; } While ( cV); | C’est une boucle avec un test en fin. Il faut la cV sont fausse, pour pouvoir sortie de la boucle. La sortie de la boucle sera effectué au moins une fois et si la cV est fausse. |
Comment créer différents tests (if, else ; switch?
a) Description :
| ALGORITHME | C++ |
| Si cV Alors / cV est vrai/ Action 1 Sinon / cV est fausse/ Action N FinSi | if (cV) {Action 1 ; }else{ Action N ; } |
| Suivant Variable_aTester faire Valeur 1 : Action U Valeur 2 : Action Z Valeur 3 : Action A Valeur 4 : Action N Autrement :TraitementParDéfaut finsuivant | Switch(Variable_aTester) { Case 1 : Action U ;break ; Case 2 : Action Z ;break ; …. Default :TraitementParDéfaut ; } |
Petites explication complémentaire à propos de la boucle (suivant … faire).
• Elle permet de générer un traitement adapte à chaque valeur particulière prise par une variable.
• Le cas « autrement », englobe l’infinité d’autres valeurs possibles pouvant être prises par la variable. Il s’agit souvent dans ce cas d’un traitement d’erreur.
• Attention : Cette structure est souvent limitée, dans les langages informatique
(ex : C, C++, Pascal) aux variables de type simple : caractère et entier et ne fonctionne pas pour des variables de type réel et chaîne de caractères.
• La commande de contrôle « switch ()» est l’équivalent d’une succession d’instructions « if ».
b) Comment fait – on pour sortir des différentes boucles ?
Pour sortir, des différentes boucles, même pour le switch, on utilisera la commande « break » qui signifie que l’on désire sortir directement de la boucle, sachant que la sortie s’effectue sans exécuter les instructions de fin de boucle.
ATTENTION : La commande « break » ne fait cependant pas sortir d’une structure conditionnelle « if ».
c) Comment peut – on passer à l’itération suivante ?
L’instruction « continue » permet de passer directement à l’itération suivante, après exécution des instructions de fin de boucle.
d) Utilisation des deux fonctions ?
Les instructions « break et continue » ne s’appliquent qu’à la boucle la plus intérieur comprenant ces instructions Elles ne permettent donc pas de sortir de plusieurs boucles imbriquées.
e) Instruction « aller à » (goto).
Il permet de brancher inconditionnellement à une ligne du programme.
Cette ligne doit avoir été étiquetée, c'est-à-dire précédée d’un identificateur suivi du symbole « : ». L’instruction « goto » a la réputation de rendre les programmes moins lisibles et plus difficiles à modifier : il est en effet souvent difficile, à la lecture du programme, de déterminer d’où l’on vient. Certains programmeurs n’ont cependant pas besoin de « goto » pour arriver à ce résultat.
L’instruction « goto » peut néanmoins se justifier pour sortir de plusieurs boucles imbriquées. Dans ce cas, l’instruction « goto » simplifie en effet le programme et le rend plus lisible.
De plus, le « goto » peut nous servir pour se déplacer dans une fenêtre graphique et se placer en un point voulut.
Ex : goto(X,Y) ; // Nous désirons se déplacer en ce point de coordonnées X et Y.
COMMENT CREER UNE FONCTION ?
1) Qu’est ce qu’une fonction ???
Le C++ permet, au développeur, de diviser son code en plusieurs morceaux. Cela s’appelle une « fonction où une instance si vous étés en objet ». Une fonction dotée d’une description simple et d’une interface bien définie peut être écrite et déboguée sans se soucier du code qui l’environne.
2) Comment la déclarée ?
Pour que cette signature soit connue avant l'utilisation de la fonction, il est nécessaire qu'elle soit placée avant l'appel de cette fonction. Il existe deux façons de procéder.
1. La fonction se situe dans le même fichier, auquel cas, il suffit de placer le texte de sa définition avant le texte de son appel comme nous venons de le faire. L'appel de la fonction peut être dans la fonction principale main() ou tout autre fonction, le tout c'est que cette dernière soit définie après la fonction appelée.
2. Vous décidez malgré tout de placer votre définition de fonction après la fonction principale ou bien même, vous placez la définition de la fonction
dans un autre fichier source. Il est alors nécessaire dans ces cas là, de proposer ce que l'on appelle une déclaration pour avoir la signature requise.
3) Que ce passe t’il quand on fait appel à une fonction ?
Lors de l'appel d'une fonction il y a suspension de l'exécution du programme principal (main) en cours. Exécution de la fonction appelée. Quand la fonction appelée est terminée, le programme principal (main) reprend son exécution à l'endroit qui suit immédiatement l'appel.
L'exécution d'une fonction se termine une fois exécutée la dernière instruction du corps de la fonction ou quand une instruction return est rencontrée dans le corps de la fonction.
4) A sert cette « liste des paramètres » ?
a) Petites précisions a propos des fonctions :
Les fonctions utilisent un espace d'allocation de mémoire située sur la pile d'exécution du programme. Cet espace d'allocation reste associé à la fonction jusqu'à ce que celle-ci se termine. Dès lors, l'espace devient automatiquement disponible pour être réutilisé.
b) Quel est l’utilité propre à cette liste de paramètres :
Chaque paramètre de fonction, ainsi que les variables internes, sont stockés sur cet espace d'allocation (place prise dans la mémoire). Ces deux valeurssont alors appelés, variables locales. Cette pile est différente de l'allocation mémoire statique, ce qui sous-entend que les valeurs des arguments passées à la fonction vont être copiées dans les paramètres et se retrouvent donc sur la pile.
Les changements effectués sur ces variables locales (donc sur la pile), ne sont pas répercutées sur les valeurs des arguments. Chaque entité possède sonpropre espace mémoire. Une fois la fonction terminée, l'espace d'allocation de la pile est supprimée pour cette fonction, et donc, les valeurs locales sont définitivement perdues. Les valeurs locales sont donc des variables dynamiques qui possèdent, malgré tout, une identité, c'est-à-dire un nom.
c) Qu’est ce que le passage de paramètres ??
Cela permet à une fonction de pouvoir traiter des données qui ne sont pas définies dans son corps. Ces données sont passées à la fonction lors de son appel. Il existe deux techniques de transmission (passage) de paramètres :
1. Soit par valeur.
2. Soit par variable, ce qui permet dans ce cas là, de se connecter directement (ou indirectement) aux variables de la fonction principale, c'est-à-dire aux arguments.
d) Développons maintenant ce que c’est la transmission par valeur :
C'est le type de transmission qui est le plus couramment utilisé. Avec ce système, la fonction manipule les copies locales des arguments. Ainsi, les fonctions n'obtiennent que les valeurs de leurs paramètres passés et elles n'ont pas accès au contenu des variables elles-mêmes. Les paramètres d'une fonction sont des variables locales qui sont initialisées automatiquement par les valeurs indiquées par les arguments lors de l'appel.
A l'intérieur de la fonction, nous pouvons donc changer les valeurs des paramètres sans influencer les valeurs originales dans les fonctions appelantes, ce qui procure une protection maximale pour les arguments. Toutefois, il peut être nécessaire d'atteindre l'argument lui-même pour permettre le changement de sa valeur. C'est la transmission par variable.
e) Qu’est ce que la transmission par variable ???
Le passage par variable permet à la fonction appelée de pouvoir modifier le contenu de la variable passée en paramètre. Il existe deux techniques pour résoudre ce problème :
Soit indirectement en utilisant les pointeurs.
Soit directement en utilisant les références
f) Petit résume de ce que j’ai énuméré ci-dessus:
• Si nous devons récupérer une valeur sans changer le contenu del'argument, il faut alors proposer une transmission par valeur.
• Si nous devons modifier directement le contenu de l'argument, il faut cette fois-ci proposer une transmission par variable en prenant si possible une référence pour que l'argument soit directement connecté.
g) Qu’est ce qu’une fonction « inline » ?
Le qualificatif « inline » peut être appliqué à une fonction. Dans ce cas, le compilateur injecte le code de la fonction plutôt que de générer un appel de fonction. Le nombre d’instructions générées est alors plus important car le code de la fonction peut se trouver duplique à de nombreux endroits du programme. Il peut cependant en résulter un léger accroissement de vitesse d’exécution car un appel de fonction casse l’effet de séquence dans un programme.
Réservez les fonctions « inline » aux fonctions de taille très limitée (max 3 lignes de code) et critique en terme de vitesse d’exécution.
Le compilateur doit avoir rencontre la fonction « inline » avant de rencontrer son appel. Pour cela, les fonctions sont souvent regroupe en début de programme.
 |
STOCKER DES ELEMENTS DANS UN TABLEAU
a) Définition :
Un tableau est une collection d'éléments d'un seul et même type. Les éléments individuels ne sont pas nommés ; on accède à chacun d'eux par leur
position dans le tableau, repéré par un indice. La taille d'un tableau est le nombre des cellules représentant chacun des éléments.
Cette taille doit être connue dès la déclaration car elle conditionne avec le type, la place mémoire allouée au tableau.
b) Déclaration d’un tableau :
ATTENTION : La dimension doit être obligatoirement supérieur à zéro.
Nous pouvons en déduire que l’on ne peut absolument pas utiliser une variable non constante pour spécifier la dimension d’un tableau.
Les « [ ] » indique simplement que c’est un tableau de n cases.
c) Comment peut-on initialiser un tableau ?
Il est possible, comme pour les variables simples, d'initialiser explicitement le tableau dès sa déclaration. Il suffit alors de préciser la liste des valeurs entre accolades séparées par des virgules.
Normalement, le nombre de valeurs initiales dans votre liste doit correspondre à la dimension de votre tableau. Toutefois, si ce nombre est inférieur, les éléments non explicitement initialisés prendront la valeur 0.
Attention : la liste des valeurs ne doit pas dépasser la dimension du tableau.
La solution, pour éviter de se tromper, c’est une des possibilités de ne pas spécifier explicitement la dimension du tableau. Le compilateur prendra l’initiative de déterminer alors sa taille grâce au nombre d'éléments listés.
Il faut bien savoir qu’un tableau qui est simplement déclaré contient des valeurs aléatoires et par conséquence peuvent engendrer des erreurs de calcul.
d) Comment faire une copie intégrale d’un tableau dans un autre ?
Lorsque vous effectuez une copie de tableau, il est judicieux de travailler avec des tableaux de même dimension.
Cependant, le C++ n’offre aucun moyen de vérifier si l’indice que vous proposez, est situé à l’intérieur de l’intervalle du tableau.
e) Quels sont les différents types pouvant se trouver dans un tableau.
Un tableau est, si je schématise, une grosse armoire avec, plusieurs tiroirs refermant des choses clair ou étrange.
Attention : Veilliez à bien faire correspondre le type du tableau avec ce que vous voulez mettre dedans.
Dans un sens, j’espère vous avoir convaincu. Mais d’en l’autre, nous pensons que c’est logique.
f) Quels sont les différents types compatibles ?
Dans un tableau, on peut mettre pas mal de choses en réalité.
Voici, quel type de déclarations très utilisées en C++.
Les chaînes de caractères : c’est quoi ça ???
Voici une explication concrète et très simple à comprendre.
Une chaîne de caractères est une collection de caractères. Comme par hasard cela ressemble à un tableau. C'est en fait un cas particulier d'un tableau de caractères, qui comporte un caractère supplémentaire de fin de chaîne qui s'appelle le caractère nul terminal ‘ \0 '. C'est un caractère de contrôle.
Un tableau de caractères peut-être initialisé soit avec une liste de caractères littéraux séparés par des virgules, soit avec une constante littérale chaîne.
Remarquons toutefois que les deux formes ne sont pas équivalentes. La différence se situe au niveau du caractère nul terminal.
ATTENTION : En réalité, une chaîne de caractères est un tableau comme un autre. Il est donc impossible d’affecter une chaîne de caractères avec une constante littérale.
Il faut aussi savoir qu’une affection n’est pas une initialisation.
La constante littérale chaîne est en fait un tableau de caractères qui ne porte pas de nom. (Ce qui signifie que cela se trouve quelque part en mémoire.)
Petite remarque très importante à mon goût, c’est nous nous trouvons dans une cas bien particulier ou l’affectation entre tableau est interdite.
Autres types pouvant se trouver dans un tableau :
Tableau d’entier.
Tableau de réel.
Structure, objet, string, etc …
g) Comment créer un tableau à plusieurs dimension ?
On a vu jusqu'à pressent, des tableaux à une seule dimension. Maintenant, nous allons voir les tableaux à multi dimension.
Qu’est ce que cela veut dire ?
Chaque dimension est spécifiée avec sa propre paire de crochets. Il peut être initialisé comme un tableau à simple dimension. Sauf qu’il faut utilisé deux itératives.
(Par exemple deux boucle For).
Petite mise a point, sur les deux boucles « for » encastrées, celle qui est à l’intérieur, au dessus du traitement, vas s’exécutés entièrement avant de revenir a la première et ainsi de suite.
Voici la bonne déclaration :
Avec : dl : Nombre de lignes du tableau
dc: Nombre de colonne du tableau.
Exemple de déclaration avec initialisation d’un tableau à deux dimensions :
Char tableau[2][10]={« Vincent », « Ludovic »}
Dans ce genre de situation, il faut être très attentif.
Nous devons faire en sorte de disposer de suffisamment de place pour que la chaîne puisse être introduite en entier. Attention au caractère terminal nul.
Pour obtenir au final avoir cette représentation : | V | i | | n | | c | | e | | n | | t | | \0 |
Avec : | | : Représente une case d’un tableau virtuel.
Dans cet exemple traiter, certaines cases mémoires ne seront peut-être jamais utilisées. Tant pis, il faut faire un choix, et il est préférable d'avoir toutes les chaînes utilisables.
LES ENUMERATIONS , LES STRUCTURES, LES UNIONS et LES STRUCTURES DE BITS
a) Les énumérations
Souvent lors d'une programmation, il est nécessaire de définir un ensemble d'attributs alternatifs à associer à un objet.
Cette approche fonctionne très bien, mais elle présente un certain nombre de faiblesses. La principale est qu'il n'existe aucun moyen de contraindre une variable
(donc de type entier) à rester sur l'une de ces trois valeurs uniquement, puisque, par définition, cette variable peut prendre beaucoup plus de valeurs dans le monde des entiers.
Les énumérations sont un moyen commode de regrouper des constantes, lorsqu'elles ont une signification voisine, ou reliée.
Les énumérations permettent donc de définir, mais également de grouper des ensembles de constantes entières.
 |
L'énumération présente l'énorme avantage de travailler avec des mots qui évoquent quelque chose plutôt que de manipuler des nombres qui en tant que tel ne veulent rien dire.
b) Les structures
b1) A quoi servent les structures ?
Les données d'un programme sont rarement dispersées. Elles peuvent en général être pensées sous la forme de groupes plus ou moins important, ayant une cohérence significative.
 |
Alors qu'un tableau recueille des éléments de même nature, une structure associe des éléments d'entités différentes. A l'inverse du tableau, chaque champ possède son propre nom, ce qui offre plus de souplesse d'utilisation.
Généralement, nous fabriquons d'abord la structure à laquelle nous associons un nom de type, et plus tard, nous déclarons toutes les variables associées à cette structure.
Exceptionnellement, nous pouvons directement déclarer une variable structurée sans lui associée de nom de type ; la structure est alors anonyme.
b2) Comment initialiser une structure ?
Comme pour les tableaux, Il est possible d'initialiser explicitement la structure dès sa déclaration. Il suffit alors de préciser la liste des valeurs entre accolades séparées par des virgules. S'il y a moins de valeurs d'initialisation que de champs dans la structure, le procédé est analogue à ce qui se passe dans les tableaux. Les champs pour lesquels il n'y a pas de valeur sont initialisés à 0. Ceci dit, il est quand même préférable de bien initialiser explicitement.
Lorsque vous avez des structures à l'intérieur d'autres structures, au moment de l'initialisation, vous vous retrouvez avec des accolades imbriquées. Vous avez la possibilité de supprimer les accolades intérieures. Toutefois, pensez à la clarté de votre code.
b3) Comment ce fait l’accès aux différentes structures ?
 |
b4) Comment utiliser les structures ?
Une fois que la déclaration est faite, nous pouvons utiliser la structure soit dans son ensemble, soit avec un des champs uniquement, comme nous venons de le découvrir.
Ce qui est très intéressant, c'est que nous pouvons affecter directement une structure vers une autre. Les champs sont alors copiés un à un, c'est ce quenous appelons une copie membre à membre. Dès lors, la deuxième structure devient un clone de la première.
Cette technique peut être appliquée également au moment de l'initialisation.
Par contre, si nous désirons changer de valeurs sur la totalité d'une structure, il n'est pas possible d'utiliser la syntaxe des accolades comme lors
d'une initialisation. Nous sommes obligés d'affecter chacun des champs séparément.
c) Les unions.
c1) Définition n°1 :
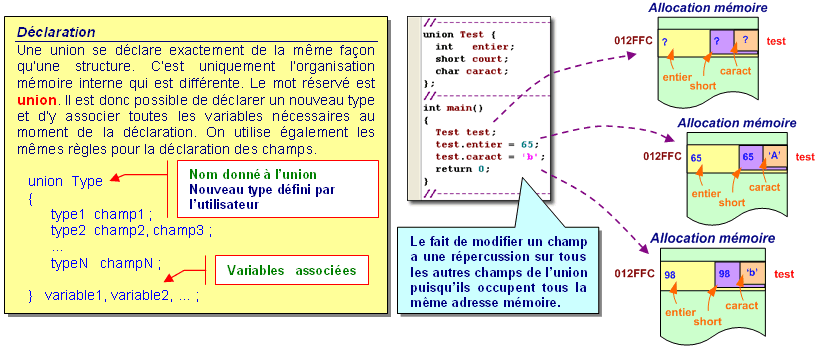
L’union est une déclaration de différentes variables qui occupent toutes la même place mémoire.
Grâce à l’union, une même zone mémoire peut être en effet être considérée soit comme un entier, soit comme une chaîne de 2 caractères soit encore comme un zone de 16bits.
Petit exemple de déclaration :
unions U {
int i ;
char c[2] ;
}u_var ;
Avec : union : Mots réservé
U : Nom donné à l’union (décrit une information, pas un variable)
{…} : zone mémoire pourra être considérée comme un entier (de nom i) ou une chaîne de 2 caractères.
u_var : Nom donné à la variable.
L’exécution du programme, une zone de la mémoire est réservée pour l’union, comme c’est le cas d’ailleurs pour toutes variable. La taille de cette zone est telle qu’elle pourra contenir le champ de plus grande taille.
c2) Définition n°2 :
Une union est une sorte de structure spéciale. Les données membres dans une union sont stockées en mémoire de façon à ce qu'elles se recouvrent. Chaque membre commence à la même adresse mémoire. La quantité mémoire allouée à une union est celle nécessaire pour contenir la plus grande de ses données membres.
Seul un membre à la fois peut être effectué d'une valeur.
 |
Lorsque nous combinons les structures de bits avec des unions, nous obtenons une grande richesse d'expression. Il sera alors possible de manipuler des données dotées d'une infrastructure très compliquée, avec au contraire, une utilisation d'une simplicité déconcertante.
! Voici deux définitions qui veulent dire la même chose, mais présenté sous deux formes totalement différentes. A vous de choisir, la mieux pour vous …!
d) Les structures de bits.
d1) Qu’est ce qu’une structure de bits ?
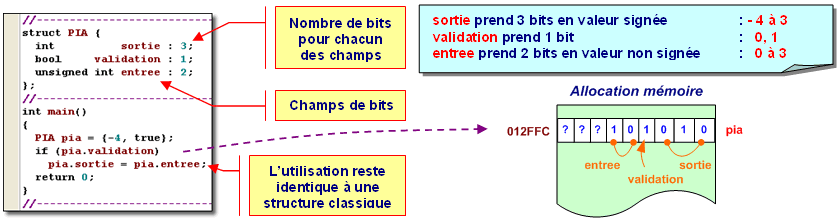
Le langage C++ (comme le C) permet de définir et manipuler des champs dont la taille est inférieure à un octet et qui se mesure en nombre de bits.
d2) Qu’est ce qu’un champ de bits ?
Un champ de bits aura un type de donnée entier (également caractère ou même booléen), signé ou non signé.
d3) Comment peut – on identifier un champ de bits ?
L'identificateur de champ de bits est suivi d'un deux points ‘ : ‘, puis d'une expression constante indiquant le nombre de bits.
d4) Qu’est ce que le champ de bits peut-il définir ?
Les champs de bits définis consécutivement, dans le corps de la structure, sont regroupés dans des bits adjacents du même entier, permettant ainsi de compresser la mémoire.
d5) De quelle manière ce fait l’accès a ce champ de bits ?
Un champ de bit est accédé de la même manière que les autres données membres d'une structure.
 |
Les champs de bits peuvent procurer des facilités dans certains cas ; ils sont surtout utiles dans des applications très techniques faisant intervenir le matériel ou les périphériques.
a) A quoi peut nous servir un pointeur et quel est son utilité ?
Un pointeur désigne une variable qui contient l'adresse d'une autre variable. On dit aussi que le pointeur renvoie ou ‘pointe' (d'où le nom) vers la variable concernée, cela via son contenu consistant en une adresse de variable. Les pointeurs sont parfois appelés ‘ indirections '.
Précédemment nous avons vu, que chaque cases mémoires étant réservées pour chaque variables, tout à sachant que le nombre de cases varie en fonction du type de la variable.
En C++, comme touts autres langages de programmation, chaque variable déclarer, se trouve quelque part en mémoire. Dans ce cas précis, on parlerad’adresse mémoire.
Il existe deux manières d’accéder à une variable ce situant en mémoire qui sont :
Î Par son noms.
Î Par son adresse, en utilisant un pointeur.
b) Comment déclarer un pointeur ?
Comme toute variable, un pointeur doit être déclaré préalablement à son utilisation et initialisé.
Un pointeur est défini en préfixant l'identificateur avec l'opérateur de déréférencement ‘ * '. Nous devons également indiquer le type de la variable pointée. En bon français, cela signifie « Ton adresse est ».
Il est possible, mais non obligatoire (contrairement aux références), d'initialiser les pointeurs. Il suffit alors d'indiquer l'adresse de la variable à pointer en utilisant l'opérateur de référence ‘ & '. En bon français, cela signifie « Dis-moi ton adresse ».
c) Qu’est ce qu’une adresse au niveau des pointeurs et de la mémoire?
Petite remarque : Il faut bien que quelqu’un soit quelque part, dit-on ?
C’est pourquoi chaque variable en C++ est stockée quelque part dans la mémoire de l’ordinateur. Nous devons savoir en tant que développeur, que la mémoire vive est constitue d’octets qui possèdent chacun leur propre adresse numérote 0, 1, 2, et ainsi de suite.
d) Que ce passe t-il si le pointeur n’est pas initialisé ?
On enfreint la règle sur les pointeurs. Cette règle est la suivante :
Un pointeur doit toujours être initialisé avant d’être utilisé pour consultation ou modification des valeurs pointées. Il n’est pas impératif que cette initialisation soit réalise au moment de la déclaration, elle peut-être faite plus tard, le tout, c’est que le pointeur soit prêt avant d’être utiliser.
Si nous désirons qu'un pointeur ne pointe sur rien momentanément, il est préférable de l'initialiser à 0.
e) Comment utiliser un pointeur ?
Voici, la réponse, il existe deux façons d'utiliser un pointeur.
1. Soit nous nous intéressons à son contenu, auquel cas, c'est l'adresse d'une variable qui nous préoccupe.
2. Soit nous décidons d'atteindre indirectement la variable pointée. Il existe un opérateur qui traite l'indirection et qui s'appelle l'opérateur de déréférencement : ‘ * '.
f) Comment se passe tout cela au niveau de la mémoire ?
Chaque pointeur possède un type associé.
La différence entre des pointeurs ne se trouve pas dans la représentation du pointeur, et pas dans les valeurs (adresses) que le pointeur peut contenir.
En effet toutes les adresses ont la même capacité mémoire.
La différence est plutôt dans le type de la variable adressée. Le type du pointeur instruit le compilateur sur la façon dont il doit interpréter la mémoire trouvée à une adresse particulière ainsi que sur la quantité de mémoire que doit couvrir cette interprétation.
g) Quels sont les opérateurs que l’on peut utiliser avec les pointeurs ?
L'opérateur d'incrémentation ‘ ++ ' agit de la même façon que sur des entiers.
Cependant, le pointeur est augmenté de une position, non de un octet. En effet, le pointeur pointe sur un type T qui a une certaine taille en octets t (t = 4 dans le cas d'un int) ; lorsqu'on écrit p++, dans ce cas, l'adresse est augmentée de t octets, afin de pointer sur un autre élément de même type supposé suivre dans la mémoire.
h) Quels sont les risques en couru si nous faisons une mauvaiseopération ?
1. La nouvelle adresse ne correspond pas au type prévu, et les nouvelles
valeurs proposées sont totalement intempestives.
2. On risque d'atteindre une adresse qui se trouve en dehors des données déclarées et qui peut, suivant le cas, soit détruire vos lignes de codes (autodestruction), soit carrément atteindre un autre programme et provoquer le même genre d'inconvénient. (Normalement, les systèmes d'exploitations récents se prémunissent contre ce genre d'agression).
i) En réalité, existe-t-il une ressemblance entre les pointeurs et les tableaux ?
Oui, on a vu précédemment qu’un tableau été représenté sous la forme d’une ligne avec n cases (simple dimension) ou bien composé de n lignes et n colonnes
(multi - dimension).
Les pointeurs ont été mis en place pour permettre de se déplacer librement au sein d'un tableau ou au travers d'une chaîne de caractères (qui est également un
tableau). La particularité d'un tableau, c'est justement de disposer de cases contigües d'un même type d'éléments.
Néanmoins, il existe qu’une seule différence. La voici :
| Tableau | Pointeur |
| Pointeur constant, mais avec une réservation d'une zone mémoire correspondant à la capacité du tableau pour stocker les données | Pointeur variable. On peut donc modifier son contenu. Par contre, il n'y a pas de réservation mémoire de la variable pointée. Cette réservation doit être réalisée au préalable. |
Malgré cela, c’est très important cette similitude entre ces deux choses très différentes. On peut avoir ce type d’écriture qui veut dire la même chose :
| En utilisant les indices | Avec l'arithmétique des pointeurs |
| int x[10] ; for (int i=0 ; i<10 ; i++ ) x[i] = i; | int x[10], *px = x ; for (int i=0 ; i<10 ; *px++ = i++) ; |
Arithmétique des pointeurs pour le tableau | Indice de tableau sur un pointeur |
| int x[10] ; for (int i=0 ; i<10 ; i++) *(x+i) = i ; | int x[10], *px = x ; for (int i=0 ; i<10 ; i++) px[i] = i ; |
Cela mérite quelques explications. Il est impératif de bien comprendre ce qui se passe au niveau du compilateur lorsqu'il analyse l'écriture d'un tableau. Revenons justement sur la variable x qui représente un tableau d'entier de 10 cases :
Attention à ce qui va suivre, c’est très important à comprendre, car c’est la marche à suivre :
x ==> adresse du premier élément du tableau ==> équivalent à &x[0]
x+1 ==> adresse du deuxième élément du tableau ==> équivalent à &x[1]
x+2 ==> adresse du troisième élément du tableau ==> équivalent à &x[2]
x+n ==> adresse du n ème élément du tableau ==> équivalent à &x[n]
Donc lorsqu'on écrit &x[n], cela veut bien dire : adresse de la case du tableau x indicé par n qui se traduit plus simplement par x+n, qui dans ce cas,
correspond plus à un décalage par rapport à l'adresse d'origine (première case du tableau). De toute façon, quel que soit l'écriture, nous sommes là en présence une adresse.
Le compilateur que l’on va utiliser, sait très bien que c’est un pointeur grâce à l’indice et il transforme cette écriture pour donner son équivalent avec l’arithmétique des pointeurs. Par exemple :
1. t [i ] le compilateur transforme systématiquement cette écriture par *(t+i)
2. t [4] le compilateur transforme systématiquement cette écriture par *(t+4)
Inversement :
*(t+4) <==> *(4+t) puisque l'addition est commutative donc ==> t[4] <==> 4[t]
j) Voici un petit exemple de ce qu’on peut faire avec un pointeur :
| Lignes de code successives | Explications |
| int a[ ] = {11, 22, 33, 44} ; | Déclaration d'un tableau de quatre entiers initialisé respectivement par les valeurs a[0]=11, a[1]=22, a[2]=33, a[3]=44. |
| int *pa, x; | Déclaration d'un pointeur sur un entier ainsi que d'un entier appelé x. |
pa = &a[0]; ou pa = a; | Copie dans pa l'adresse de la première case du tableau. Comme le nom du tableau correspond justement à un pointeur constant sur la première case du tableau, la deuxième écriture est préférable puisque plus concise. Le nom d'un tableau, sans référence à un indice, peut être utilisé dans un programme, à condition de le considérer comme une constante. |
| x = *pa; | Copie le contenu de l'entier pointé par pa (c'est-à-dire a[0] ) dans x. x <== 11 |
| pa++; | pa est incrémenté d'une unité et contient maintenant l'adresse de la deuxième case du tableau, c'est-à-dire l'adresse de a[1]. pa = &a[1] |
| x = *pa; | pa pointe sur a[1], *pa est le contenu de a[1] . x <== 22 |
| x = *pa + 1; | Copie dans x la valeur a[1]+1. x <== 23 |
| x = *(pa+1); | Comme les parenthèses sont prioritaires par rapport à l'opérateur d'indirection, le calcul intermédiaire pa+1 est effectué en premier, ce qui donne comme résultat l'adresse de a[2] puisque l'unité d'incrémentation est la taille de la variable pointée. L'entier contenu à cette adresse (c'est-à-dire a[2] ) est copié dans x. x <== 33 Notez que si pa intervient dans le calcul, il n'est pas modifié, pa pointe toujours sur a[1]. |
| x = *++pa; | En vertu des règles de priorité des opérateurs ( * et ++ sont de niveau 2), l'opération la plus à droite est d'abord effectuée, c'est-à-dire ++pa . pa , qui est modifié par cette opération, contient maintenant l'adresse de a[2] . pa = &a[2] L'opération d'indirection * est ensuite effectuée. x contient dès lors a[2]. x <== 33 |
| x = ++*pa; | *pa est d'abord évalué. pa pointant sur a[2], *pa est a[2]. La cellule a[2] est soumise à incrémentation, toujours de 1 car a[2] n'est pas un pointeur mais bien un entier. x <== a[2] <== 34 Bien que l'on ait à faire à une préincrémentation, * est prioritaire par rapport à ++ car ces deux opérateurs se situent au niveau 2 de priorité. Or, à ce niveau, l'opérateur le plus à droite dans l'expression est prioritaire. |
| x = *pa++; | La postincrémentation, même si elle paraît prioritaire ici, n'est effectuée qu'en dernier lieu, par définition de la postincrémentation. Les règles de prorité indiquent cependant que l'opération ++ porte sur pa et non sur *pa. Le contenu de *pa (c'est-à-dire 34) est copié dans x. x <== 34 pa est ensuite incrémenté et contient maintenant l'adresse de a[3]. pa = &a[3] |
k) Comment est désigné un pointeur?
p = ? // désigne le contenu du pointeur &p = ? // désigne l'adresse du pointeur *p = ? // désigne le contenu de la variable pointée. |
l) Autres utilisations des pointeurs ?
Tout cela et parfait, mais il reste une chose, c’est que les pointeurs sont utilisés pour des chaînes des caractères. On utilise un pointeur pour référencer une chaîne. Si on décide de prendre un tableau, il faut obligatoirement réserver une place suffisante en mémoire pour évite de faire de l’auto-destruction. Sinon, si on a besoin que d’une seule valeur de chaîne qui servira généralement de message, à ce constante littérale.
Rappel : Une constante littérale chaîne est un tableau de caractères qui ne porte pas de nom et qui se trouve quelque part en mémoire.
Petit exemple qui peut faire comprendre cela :
char texte[7] = « Salut » ; // tableau de caractères char *message = « Bonjour » ; // pointeur vers un caractère |
 |
La variable message est un pointeur de caractère, il est donc tout à fait possible de changer sa valeur au cours du temps.
Attention toutefois, cela reste un pointeur, ce n'est pas une chaîne de caractères en tant que tel.
Si vous proposer une nouvelle affectation, vous ne copiez pas la nouvelle chaîne, vous pointez vers cette nouvelle chaîne. Par ailleurs, si vous faites cette affectation, l'adresse de la chaîne précédente est perdue, ce qui fait que l'ancienne chaîne n'est plus du tout accessible.
 |
m) Qui sont t-il ?
On a tout d’abord le type « void » (vide ou rien). Il est possible de déclarer des pointeurs tout en spécifiant que le type de la variable pointée est indéterminé.Un tel pointeur peut recevoir une adresse mais ne peut être l’objet d’opérations *, ++, -- sauf si le type de la variable pointée est spécifié par un« casting ».
On trouve aussi des pointeurs constants. Il faut savoir que le « const » peut qualifier un pointeur. Puisque « const » peut également qualifier la variable pointée, il faut être attentif à la position de « const » dans la déclaration.
« const » qualifie le mot immédiatement à sa droite.
a) Comment est réellement gérer et organiser la mémoire interne au PC ?
En C++ les variables peuvent être allouées de deux façons différentes qui sont :
1. Soit statiquement : Avant l'exécution du programme, le compilateur traite le code source et détermine l'ensemble des variables et réserve un emplacement mémoire en conséquence. La durée de vie de ces variables correspond à la durée de vie du programme. La zone d'allocation est soit la zone statique, soit la pile (pour les variables locales).
2. Soit dynamiquement : Cette fois-ci, pendant l'exécution du programme, il est possible d'avoir besoin d'une variable pour une utilisation relativementbrève dans le temps. Une variable est alors créée à la volée et elle sera détruite quand le besoin ne s'en fera plus sentir. La zone d'allocation est le tas.
Malgré tout cela, il faut savoir une chose de très important, c’est la différence entre les deux.
b) Qu’est ce que l’on entend par cette différence ?
1. L'allocation de mémoire statique est considérablement plus efficace car effectué avant le commencement du programme. Quand le programme démarre, tout est prêt pour fonctionner correctement et les variables sont très faciles à atteindre et à manipuler. Et de plus, le temps de réponse est des plus rapide.
2. L’allocation de mémoire dynamique est toutefois moins flexible car elle nécessite de connaître, avant l'exécution du programme, la quantité et le type de mémoire désirés.
c) Comment définir ces deux types très différents dans nos lignes de codes ?
Jusqu’ à présent, nous avons vu essentiellement des variables statiques qui sont facile à nommées et à manipuler. Alors que les variables dynamiques sontdes variables « anonyme » manipulées indirectement au travers de pointeurs.
d) Que se passe t’il au niveau de la mémoire vive ?
Pour les variables statiques, la gestion se fait automatiquement par le compilateur, au démarrage de notre programme et à la fin de celui – ci. On peut, en clair, dire que ces variables ont une durée de vie égale au programme.
Pour les variables dynamiques, la gestion se fait tout autrement. A savoir, il faut explicitement gérées plus souvent ces variables pour éviter de générer un tas d’erreur qui peut vraiment influer sur le programme en lui-même.
ATTENTION : Pour gérer, les variables dynamiques, on utilise deux opérateurs qui sont : « new » et « delete ».
e) Que signifient ces deux opérateurs ?
L'opérateur new s'occupe de l'allocation dynamique. Pour qu'il soit à même de réserver un emplacement suffisant, il faut lui indiquer le type correspondant.
Le type indiqué avec l'opérateur new doit être de même nature que le type géré par le pointeur.
Il est impératif de libérer la mémoire lorsque nous avons fini de nous servir d'une variable dynamique.
Sinon, tout le principe que nous venons d'évoquer ne servirait absolument à rien. La mémoire libérée peut servir ensuite pour les autres variables dynamiques. Par ailleurs, il ne faut pas oublier que pour un système multitâche, les autres applications ont besoin elles-mêmes de mémoires pour fonctionner, la mémoire étant partagée pour tous les processus.
Pour libérer une mémoire allouée dynamiquement, il suffit d'utiliser l'opérateur delete. Toutefois, cet opérateur a besoin de connaître l'emplacement de la mémoire à libérer. Comme elle est anonyme, encore une fois, il est nécessaire de passer par le pointeur. Pour libérer un tableau dynamique, il suffit de placer les crochets à côté de l'opérateur delete sans précision de la dimension.
f) Quelles sont les zones d’allocation mémoire ?
On vient de voir une opposition entre les termes statiques et les termes dynamiques, en aucun cas aux zones mémoires dédiées.
Il existe en réalité trois zones mémoire prévues pour l’ensemble des variables utilisées dans un programme, la quatrième ont pourra la voir au chapitre « pointeur this » :
1. la zone statique
2. la pile
3. et le tas
Les variables statiques évoquées dans ce cours concernent aussi bien la zone statique que la pile, alors que les variables dynamiques sont créées uniquement dans le tas.
g) Petite représentation de ce qu’il y a ci-dessus.
 |
h) Comment sont gérées ces différents emplacements mémoire ?
Jusqu'à présent nous nous sommes pas rentrer particulièrement dans les différents détaille de la gestion des différents emplacement mémoire.
Intéressons nous maintenant à l’organisation et à la gestion de ces différents emplacements mémoire, voyons où cela nous mène et essayons d’ y comprendre un minimum de chose.
! Cela est très important à savoir car cela va nous éviter des erreurs de Windows ou autre OS que vous utilise. !
h1) Gestion de la pile et du tas.
La pile évolue des adresses hautes vers les adresses basses (les variables locales déposées sur la pile le sont en commençant par le haut).
Le tas évolue des adresses basses vers les adresses hautes. Cette technique présente l'avantage que, pour une même zone de mémoire allouée à l'ensemble « pile+tas », nous pourrons avoir, selon le moment de l'exécution du programme, soit une pile importante et un tas limité, soit une pile limitée et un tas important.
ATTENTION : Une situation de dépassement de capacité de pile survient lorsque le sommet de la pile rejoint le sommet du tas. Cela peut engendrer des messages d’erreur sous windows.
h2) Comment ce retrouver dans ces emplacements mémoire ?
Pour se retrouver dans les différents emplacements mémoire, on utilise un opérateur de portée.
h3) Qu’est ce qu’un opérateur de portée ?
Dans le langage C++, cet opérateur de portée est représenté sous la forme « :: » car ils indiquent la portée de la classe à laquelle le membre appartient. Les noms de classe qui précède ces signes sont l’équivalent d’un nom de famille, tandis que le nom de fonction qui les lui serait le prénom. L’ordre est similaire à celui de l’état civil officiel : le nom d’abord, puis le prénom.
Vous pouvez utiliser l’opérateur « :: » pour décrire une fonction nom membre à l’aide d’un nom de classe vide. Il est par exemple possible de se référer à la fonction non - membre. C’est comme une fonction sans domicile fixe.
Voyons un petit exemple d’illustration :
 |  |
Dans cet exemple, les variables utilisées sont déclarées dans des portées différentes. A ce sujet, la variable index est dans une portée extrêmement limitée puisqu'elle n'existe que durant la mise en œuvre de l'itérative for.
Cette variable est une variable locale, elle est donc située sur la pile. Nous avons fréquemment des imbrications de portées locales (une portée à l'intérieur d'une autre portée).
La résolution de nom dans une portée locale se déroule ainsi : la portée immédiate dans laquelle le nom est utilisé est recherchée. Si la déclaration est trouvée, le nom est déterminé ; sinon, la portée englobante est examinée. Ce processus se poursuit jusqu'à ce qu'une déclaration soit trouvée ou que la portée globale soit examinée. Dans ce cas et si aucune déclaration n'est trouvée pour le nom, l'utilisation du nom provoque une erreur de compilation.
Grâce à ce système de résolution de nom, chaque portée peut définir ses variables comme elle l'entend sans se soucier du nom. Il est alors possible de déclarer plusieurs fois le même nom de variable dans des portées différentes. A cause de l'ordre dans lequel les portées sont examinées lors de la résolution de nom, une déclaration dans une portée englobante se retrouve cachée par une déclaration du même nom déclarée dans une portée imbriquée.
Dans notre exemple, nous avons effectivement déclarés deux variables i, dont la première est une variable globale et la seconde est une variable locale (Nous aurions même pu choisir une troisième variable i comme nom de compteur d'itérative au lieu d'index, puisque la portée est également différente).
Du coup, au sein de la fonction, il n'est plus possible d'atteindre la variable globale puisqu'elle est cachée par la variable i locale.
Si, malgré tout, nous désirons communiquer avec la variable i globale, il faut alors utiliser l'opérateur de portée « :: » . Il est évident que pour éviter ce genre de problème, il est souvent préférable de choisir des noms différents pour vos variables.
h4) Comment est effectuée la gestion de ces deux espaces de mémoire qui sont le pile et le tas ?
Cette gestion se fait grâce à un pointeur. On appel cela de la gestion indirecte. Néanmoins, les deux pointeurs peuvent se gérer automatiquement ou bien manuelle (ceci dit entre développeur c’est un comportement anarchiste !!!!!).
 |
a) Comment fonctionne et s’effectue ces différentes étapes ?
Jusqu'à présent, les programmes que nous réalisons sont de toute petite dimension. Cependant, notre programme peut faire plus de 1000 lignes. Cela n'est pas envisageable, que toutes ces lignes soient écrites sur un seul et unique
fichier. C'est trop difficile à maintenir et lorsque que nous devons modifier une seule ligne, il est nécessaire de tout recompiler, ce qui représente un temps considérable vu le petit changement réalisé.
Par ailleurs, pour faciliter l'élaboration d'un projet, il est préférable de le découper et de le structurer en plusieurs fonctions. Cette approche a également le mérite de favoriser le travail en équipe. Toutefois, pour que cela soit vraiment efficace, il faut découper le projet en plusieurs fichiers, pour que chacun s'occupe de sa propre tâche.
Pour bien comprendre les mécanismes en jeu, nous allons revenir sur la notion de compilation. Rappelons que la compilation consiste à réaliser une traduction d'un langage de programmation vers le langage binaire, le seul qui soit compréhensible par le microprocesseur.
Cette compilation s'effectue en trois phases :
1. La première phase consiste à effectuer des changements de texte dans le code source, pour les constantes et les directives de compilations ( « # » ).C'est le préprocesseur qui effectue cette opération.
2. Une fois que le texte définitif est en place, le code source est ensuite analysé pour être traduit en binaire. Cette traduction est alors placée dans un fichier  séparé, appelé fichier « objet » . C'est la phase de compilation.
séparé, appelé fichier « objet » . C'est la phase de compilation.
3. Pour finir, la troisième phase rassemble les morceaux (les différents fichiers objets) afin d'obtenir un seul et unique fichier qui sera l'exécutable. C'est laphase d'édition de lien.
b) Mais que signifie le mot « préprocesseur ?
Grâce à toutes ces techniques, nous avons beaucoup progressé dans l'élaboration d'un projet. La situation est devenue assez satisfaisante, mais pas tout a fait. Imaginons que nous ayons besoin d'une dizaine de fonctions issues d'une bibliothèque. (Voir chapitre suivant sur les bibliothèques.) Nous sommes obligés de déclarer systématiquement ces dix fonctions à chacun des fichiers que nous développons. Cette démarche devient fastidieuse. Il est préférable que ces déclarations soient faites automatiquement en liaison avec la bibliothèque utilisée.
c) Mais que signifie le mot « compilateur » ?
Le « compilateur » traduit le texte du programme en un module, non encore exécutable, dit module objet, qui est une fichier d’extension « *. obj ».
d) Mais que signifient les mots « éditeur de liens » ?
L’éditeur de liens (aucun rapport avec l’éditeur de texte) combine différents modules objet pour en faire un module exécutable : il faut en effet injecter dans le module objet qui vient d’être crée des fonctions pré compilées par C++BuilderX et qui vous sont fournies sous forme de fichiers d’extension « *.obj » et de fichier d’extension « *.lib ».
C’est notamment le cas pour les fonctions d’entrée/sortie qui sont contenues dans un fichier d’extension « *.h » range dans le sous - répertoire « include » de l’installation de C++ BUILDER X.
e) Que ce passe t’il si votre programme contient des erreurs ?
Ma fois, c’est une bonne question, dont je vais vous donnez la réponse.
Les erreurs peuvent être détectées soit par le compilateur, soit par la partie éditeur de liens. Les messages d’erreur ou d’avertissement sont affichés dans la fenêtre des messages. (Dans le cas de C++ BUILDER X, c’est en dessous de votre code.)
Par un avertissement (warning) signale une expression syntaxiquement correcte mais à priori suspecte.
Accordez toujours une grande attention à ces avertissements.
Pour les autres erreurs, celles qui sont en rouge, sont en résoudre en priorité, car c’est des erreurs très graves.
Petits conseils de développeur :
Î Avant de code, il faut avoir fait un algorithme, et ce le représenter dans la tête, ce que l’on a fait sur papier avant la phase codage.
Î Pour éviter trop de compilation, je vous conseil de corriger un maximum d’erreurs avant de recompiler, mais aussi de prendre quelques minutes de relecture.
Î La relecture est très importante à mon goût pour ne pas oublier de la faire.
Î Quand vous sentez que vous en avez marre de ne pas trouver la solution à une petite erreur, je vous conseil de prendre une pause, de faire autre chose, de sortir prendre un bon bol d’aire et de boire un bon coup.
Comment crée une bibliothèque, et des fichier « *.h » en C++ ?
a) – Définition.
Les bibliothèques sont aussi souvent appelées des librairies. D'ailleurs, l'extension proposée est « *.lib ». A ce sujet, il faut savoir que systématiquement, les outils de développement intégrés, place au moins une librairie qui stocke toutes les définitions des fonctions standards du langage C++ comme les fonctions d'affichage, de saisie, etc. Cette librairie s'appelle « c.lib » (suivant les outils, le nom peut être différent, mais il y a toujours la lettre c dedans). C'est notamment pour cette raison que la taille du fichier exécutable peut sembler conséquente.
b) - Expliquons comment crée des bibliothèques ?
Les environnements de développement intégrés permettent de créer de nouvelles bibliothèques. Dans le projet, au lieu de fabriquer un exécutable, nous demandons à la place de fabriquer une bibliothèque.
Une bibliothèque est constituées d’un regroupement de fichier « *.obj ». Le contenu des point « *.obj » sont copié intégralement et à l’identique les uns à après les autres dans le fichier « *.ib ».
Dans notre exemple, nous allons mettre en œuvre une bibliothèque « Mathématique ».
Une fois que la bibliothèque est créée, il est possible de l'utiliser dans n'importe quel projet
c) - Synoptique de ce que j’ai expliquer ci-dessus :
 |
 |
 |
Nous venons de voir comment créer les fichiers en-tête, puis les différentes phases de compilations. Maintenant, nous allons voir les directives d’inclusions.
! C’est bien quand même complexe, tout cela ? Vous ne trouvez pas ? Je crois personnellement que si ! !
d) – Qu’est ce qu’une directive d’inclusion ???
Il faut maintenant que le contenu du fichier en-tête soit copié automatiquement dans le fichier source requérant ces déclarations. Il s'agit d'une copie de texte, et c'est le préprocesseur qui s'occupe de ce genre d'intervention. Dans ce cas, il faut indiquer au préprocesseur le traitement à réaliser en utilisant desdirectives appropriés. Les directives du préprocesseur sont spécifiées par un dièse « # » dans la toute première colonne d'une ligne de programme.
Pour l'inclusion, il faut utiliser la directive « #include » suivi du nom du fichier à inclure. Il existe trois syntaxes :
1. #include ''iostream.h'' : le préprocesseur recherche le fichier à inclure dans le répertoire du projet ou le répertoire courant.
2. #include : le préprocesseur recherche le fichier à inclure dans le répertoire prédéfini pour tous les fichiers en-têtes. Il s'agit du répertoire "Include" qui est créé systématiquement par tous les outils de développement.
3. #include : la recherche est la même que précédemment, mais le préprocesseur prend en compte les espaces de noms (ce sujet sera traité ultérieurement).
e) Quelles sont, d’après vous, les autres directives de compilation ?
Dans tous vos programmes, vous faite appel à des inclusions que vous allez réutiliser ailleurs, vous remarquez malgré tout qu'un même fichier en-tête peut être sollicité plusieurs fois. Du coup, le temps de compilation peut augmenter considérablement par ces ouvertures successives.
Surtout pour relire systématiquement les mêmes choses alors que le préprocesseur, lui, est capable de mémoriser les déclarations qui ont déjà été faites. Il est souhaitable de prévenir ce genre de problème en proposant des compilations conditionnelles.
| Constantes symboliques | |
| #define identificateur | Permet de définir un paramètre de nom identificateur qui pourra être utilisé dans une clause #if. Tant que le préprocesseur n'est pas passé sur cette ligne, l'identificateur n'est pas encore connu. Par contre, après lecture de cette ligne, cet identificateur est définitivement validé (sauf avis contraire grâce à la directive #undef ). |
| #define PI 3.141592 | Sert à effectuer un changement de texte en remplaçant un symbole par un autre ou par une constante. Chaque fois que le symbole PI sera rencontré, le préprocesseur le remplacera par la constante 3.141592. il est toutefois préférable d'utiliser const pour gérer les constantes. |
| Compilation conditionnelle | |
| Les directives conditionnelles permettent d'incorporer ou d'exclure de la compilation des portions de texte de programme selon que l'évaluation de la condition donne vrai ou faux comme résultat. | |
| #ifdef identificateur | Inclusion du texte qui suit cette ligne si l'identificateur est connu, c'est-à-dire s'il a déjà été défini. |
| #ifndef identificateur | Inclusion du texte qui suit cette ligne si l'identificateur n'est pas encore connu. |
| #else | Clause sinon associée à #ifdef ou à #ifndef |
| #endif | Fin du si associé à #ifdef ou à #ifndef |
| #undef | Met fin à l'existence d'un identificateur associé à un #define |
Programmation Orienté Objet
a) Que signifie cela ???
De manière simpliste, le terme « orienté objet » signifie que l'on organise le logiciel comme une collection d'objets dissociés (qui ne
connaissent pas entre eux) comprenant à la fois une structure de données – attributs (paramètres concernant cet objet) - et un comportement – méthodes(instance, ou bien une fonction) - dans une même entité.
Exemple : une voiture peut avoir une certaine couleur et en même temps possède un comportement qui sera le même pour toutes les autres voitures, comme accélérer.
b) Qu’est ce qu’un objet et comment il est constitué ?
Chaque objet possède une identité et peut être distingué des autres.
Le terme identité signifie que les objets peuvent être distingués grâce à leurs existences inhérentes et non grâce à la description des propriétés qu'ils peuvent avoir.
Nous utiliserons l'expression « instance » d'objet pour faire référence à une chose précise, et l'expression « classe » d'objets pour désigner un groupe de choses similaires.
En d'autres termes, deux objets sont distincts même si tous leurs attributs (nom, taille et couleur par exemple) ont des valeurs identiques.
Par ailleurs, un objet évolue au cours du temps. Chaque objet possède un état qui correspond à la valeur de ces attributs à un instant donné.
Objet = Identité + Etat + Comportement
c) Qu’est ce qu’une classe ?
La classification signifie que les objets ayant la même structure de donnée – attributs - et le même comportement - méthodes - sont regroupés en une classe.
Les objets d'une classe ont donc le même type de comportement et les mêmes attributs. En groupant les objets en classe, on abstrait un problème.
Les définitions communes (telles que le nom de la classe et les noms d'attributs) sont stockées une fois par classe plutôt qu'une fois par instance.
Les méthodes peuvent être écrites une fois par classe, de telle façon que tous les objets de la classe bénéficient de la réutilisation du code.
Une classe est un modèle utilisé pour créer plusieurs objets présentant des caractéristiques communes.
Chaque objet possède ses propres valeurs pour chaque attribut mais partage noms d'attributs et méthodes avec les autres objets de la classe.
d) Qu’est ce qu’un attribut ?
Un attribut est une valeur de donnée détenue par les objets de la classe.
Chaque attribut à une valeur pour chaque instance d'objet. Les instances peuvent avoir des valeurs identiques ou différentes pour un attribut donné. Chaque nom d'attribut est unique à l'intérieur d'une classe.
Dans une classe, les attributs sont définis par des variables. Les attributs peuvent être considérés comme des variables globales pour chaque objet de cette classe.
ATTENTION : Comme pour toutes variables, il est nécessaire de connaître le type correspondant et c'est la classe de l'objet qui indique de quel type d'attribut (variable) il s'agit. Chaque objet stocke sa propre valeur pour chacune de ses variables.
e) Qu’est ce qu’une méthode ?
Une méthode est une fonction ou une opération qui peut être appliquée aux objets ou par les objets dans une classe.
Tous les objets d'une même classe partagent les mêmes méthodes. Chaque méthode a un objet cible comme argument implicite (c'est l'objet lui-même « this » , elle peut donc accéder à chacun des attributs).
Le même nom de méthode peut s'appliquer à des classes différentes, vu que la portée de la méthode est sa classe. Une méthode peut avoir des arguments, en plus de son objet cible.
f) Petit retour en arrière.
Précédemment, nous avons vu comment faire de la programmation structurée, comment faire un programme principal utilisant un *.h et un *.cpp.
Cette méthode est longue et relativement lourde quand nous avons plusieurs classes (structures) objet (*.h et *.cpp) que l’on veut utiliser via un programme principal.
Maintenant voyons une autre méthode de construction nettement plus clair mais un peu plus compliquée, nous amenant à la même solution.
Petit exemple à coder et utiliser le debugger:
Avant de créer nos premiers objets, nous allons mettre en œuvre une structure qui représente un nombre complexe. A cette structure, nous allons lui associer des fonctions qui vont respectivement permettre de déterminer le module et l'argument de ce nombre complexe.
 |
Ce programme fonctionne très bien, mais cette approche présente quelques inconvénients. En effet, nous avons une séparation entre la structure d'une part, et les fonctions associées à cette structure d'autre part, alors que normalement tous ces éléments s'intéressent au même problème, c'est-à-dire, aux traitements des nombres complexes.
Si nous prenons le nom de la fonction module ; ce nom peut aussi bien évoquer le module d'un nombre complexe ou peut-être le module d'un vecteur. Heureusement, la signature de la fonction nous indique qu'il s'agit bien d'une connexion à une structure Complexe.
Enfin, lorsque nous fabriquons des fonctions qui gèrent des structures, il est systématiquement nécessaire de passer en paramètre la structure concernée. Cette façon de procéder présente l'énorme inconvénient d'avoir un temps de réponse conséquent et d'utiliser de la mémoire supplémentaire pour stocker momentanément cette structure sur la pile.
g) Voici une approche orientée objet.
Pour toutes les raisons que nous venons d'évoquer, il serait souhaitable que les fonctions module et argument soient intégrées directement dans la structure.
D'une part, le traitement demandé concerne cette structure. Par ailleurs, vus que ces fonctions sont à l'intérieur de la structure, elles peuvent atteindre
directement les champs réel et imaginaire.
Le fait que tout soit intégré, les champs sont appelés des attributs, les fonctions sont appelées des méthodes.
 |
Nous pouvons remarqué que, cette fois-ci, les méthodes ne possèdent pas de paramètres. Tout ce qu'elles ont besoin se situe dans la classe. Les attributs sont directement accessibles aux méthodes (et uniquement par elles d'ailleurs). En fait, les attributs et les méthodes sont sur la même portée, c'est-à-dire, la classe.
Ces méthodes sont là pour permettre la communication avec l'extérieur.
Souvent deux cas se présentent :
1. Un élément externe a besoin d'un renseignement, il fait donc appel à la méthode adaptée (généralement elle ne possède pas de paramètres) qui retourne l'information désirée. C'est le cas des méthodes module et argument.
2. L'objet doit changer d'état. Il faut alors utiliser une méthode qui récupère une ou plusieurs valeurs depuis l'extérieur. Cela sous-entend que nous ayons besoin cette fois-ci de paramètres à la méthode pour récupérer les arguments demandés. Généralement ce type de méthode ne renvoie rien, puisque le but poursuivi est de modifier la valeur des attributs pour arriver à ce changement d'état.
Tout ce que nous avons appris sur les fonctions s'applique pour les méthodes. Du point de vue du langage C++, une méthode reste une fonction, sauf qu'elle est intégrée dans une classe.
h) Qu’est ce que l’encapsulation ?
L'encapsulation est le principe qui permet de regrouper les attributs et méthodes au sein d'une classe.
Cette notion est aussi associée au dispositif de protection qui permet de contrôler la visibilité d'un attribut ou d'une méthode.
En d'autres termes, cela signifie que chaque fois que vous définissez un membre d'une classe (attribut ou méthode), vous devez indiquer les droits d'accès quant à l'utilisation de ce membre.
Ce mécanisme d'encapsulation permet surtout de protéger l'objet de toute malveillance externe. Pour cela, la plupart du temps.
Il faut interdire l'accès direct aux attributs et passer systématiquement par les méthodes.
i)Quel est ce dispositif de protection ?
En C++ ; il existe trois niveaux de protection :
public : Tous les attributs ou méthodes d'une classe définies avec le mot clé « public » sont utilisables par tous les objets. Il s'agit du niveau le plus bas deprotection. Ce type de protection est employé pour indiquer que vous pouvez utiliser sans contrainte les attributs et les méthodes d'une classe.
private : Tous les membres d'une classe définis avec le mot clé « private » sont utilisables uniquement par les méthodes de la classe. Cette étiquette de protection constitue le niveau le plus fort de protection. Généralement les attributs doivent être déclarés comme privées.
protected : Tous les membres d'une classe définis avec le mot clé « protected » sont utilisables uniquement par les méthodes de la classe et par les méthodes des classes dérivées (par les enfants*).
* : Nous verrons cela plus tard, plus particulièrement en deuxième année quand nous attaquerons le cour sur les objets hérités.
Par défaut, une structure possède le niveau de protection le plus faible, c'est-à-dire que tous les membres sont publics.
En fait, pour être sûr de respecter le principe d'encapsulation, il est généralement préférable d'utiliser une structure qui est privée par défaut. Il s'agit de la structure class. Dorénavant, nous utiliserons le mot réservé class plutôt que struct.
Petite illustration :
 |
 |
j) Comment peut on regrouper plusieurs *.h et *.cpp ?
Pour cela, on va utiliser une espace de noms.
j1) Qu’est ce qu’un espace de nom ?
Un espace de nom est un paquetage qui regroupe des classes et des fonctions dans une même entité, généralement représentant le même domaine.
Le paquetage fait un peu penser à une bibliothèque. Il peut d'ailleurs être judicieux d'associer un paquetage à une bibliothèque. Le symbole du paquetage est un répertoire. Ainsi pour atteindre un des éléments (classes ou fonctions), il faut
le référencer au travers du paquetage.
Si deux classes comportent le même nom, la localisation ne pose plus de problème puisqu'elles sont situées dans des paquetages différents ce qui évite tout conflit de nom.
j2) Comment définir un espace de nom ?
Pour définir un nouveau paquetage (espace de nom), il suffit d'utiliser le mot réservé « namespace » et de placer entre les accolades tous les éléments qui font partis de ce paquetage. Il est possible de spécifier le même paquetage dans plusieurs fichiers. Il suffit, tout simplement d'indiquer l'espace de nom et, à chaque fois, d'introduire les éléments concernés entre les accolades.
Pour illustrer mes propos, je vous propose de fabriquer un paquetage qui comportera la classe Complexe ainsi que deux fonctions paire et impaire. Nous nommerons ce paquetage Mathématique
 |
j3) A quoi correspond la déclaration « using » ?
Avec cette écriture, il n'est plus possible d'avoir de conflit, puisque nous précisons bien que nous prenons tel élément de tel espace de noms. Lorsque nous sommes sûr de ne pas avoir de conflits pour certains éléments, il est quand même embêtant d'avoir une syntaxe aussi lourde. Il serait préférable d'indiquer dès le départ les éléments que nous souhaitons utiliser. Vous devez alors, grâce au mot réservé « using » lister les éléments que vous souhaitez atteindre directement sans le préfixe de l'espace de nom.
 |
j4) A quoi correspond le declarative « using » ?
Finalement, il est peu fréquent d'avoir des conflits. Il est quand même souhaitable de prévoir au cas où. Cela ne coûte pas grand-chose. Toutefois, si nous sommes sûr qu'aucun des éléments de l'espace de noms ne présente de conflit avec l'extérieur, il serait plus intéressant de les rendre accessible en spécifiant le paquetage tout entier.
 |
j5) Espace de noms anonymes ?
En C++, nous pouvons utiliser un espace de noms non nommé pour déclarer une entité locale à un fichier. Cela sous-entend que cette entité ne sera plus du tout accessible depuis un autre fichier. Cette entité est donc privée. Elle ne peut être utilisée que par les autres entités du même fichier.
 |
j6) Quels sont les espaces de noms par défauts ?
En fait, tous les composants de la bibliothèque standard C++ sont déclarés et définis dans un espace de nom standard appelé « std ». Toutefois, avec la compilation conditionnelle, cet espace de nom n'est pas prise en compte lorsque nous effectuons l'inclusion suivante :
#include
Si nous désirons que l'espace de nom « std » soit effectivement intégré, il faut plutôt préciser l'inclusion suivante :
#include
Du coup, il sera nécessaire de préfixer chacun des éléments pour pouvoir les atteindre. Ainsi, pour atteindre l'objet « cout », il sera nécessaire d'écrire « std ::cout ». Du coup, pour éviter cette spécification, il vaut mieux utiliser la directive « using ». En fait, nous utiliserons fréquemment la syntaxe suivante :
#include
using namespace std ;
Maintenant nous allons voir une petite illustration sur ce que j’ai expliqué ci-dessus.
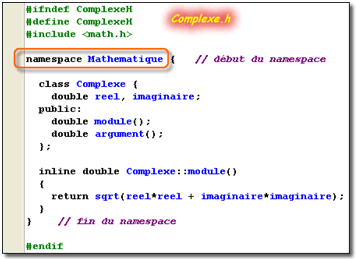 |
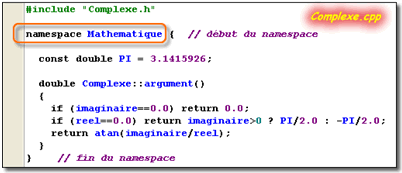 |
 |
Constructeur d’Objet
a) Introduction :
On a vu le principe d'encapsulation, il est formellement interdit d'atteindre directement les attributs d'une classe. Il faut systématiquement passer par une méthode. Cette technique est judicieuse puisque le changement d'état d'un objet passe d'abord par un changement de comportement.
Du coup, il n'est pas possible de réaliser une initialisation explicite en utilisant les accolades comme nous avions l'habitude de procéder avec les structures.
Ne vous inquiétez pas, il existe des méthodes adaptées pour résoudre les initialisations explicites pour que l'objet soit dans l'état désiré. Ces méthodes spécifiques s'appellent des constructeurs.
b) Qu’est ce qu’un constructeur ?
Un constructeur est une méthode (fonction membre) qui sera automatiquement appelée à chaque création d'un objet.
Sa tache principale consiste à initialiser l’objet à une valeur de départ qui soit légale pour cette classe.
Ceci se fera quel que soit la classe d'allocation de l'objet : statique, automatique (pile) ou dynamique (tas). Le constructeur se reconnaît parce qu'il porte le même nom que la classe.
Attention : un constructeur ne doit rien renvoyer. Cela n'aurait aucun sens puisque c'est la phase de création.
c) Créations d’objets à partir des constructeurs.
Un constructeur est une méthode, donc, lorsque nous créons un objet, nous devons faire appel explicitement à cette méthode, en utilisant la syntaxe habituelle de l'appel des fonctions, c'est-à-dire en utilisant les parenthèses.
Pour le nombre complexe, nous avons besoin de préciser les deux arguments vu la signature du constructeur que nous avons choisi.
Nous savons que nous avons la possibilité d'initialiser explicitement une variable dynamique. Dans le cas d'une variable primaire (int - par exemple), il s'agit dans la syntaxe de préciser le type de la variable et de donner entre parenthèse la valeur initiale.
Dans le cas d'un objet, il est nécessaire de passer par la phase de création. Nous faisons donc appel explicitement au constructeur avec le nombre d'arguments requis.
d) Quelles sont les mécanismes disponibles grâce à une classe ?
Le mécanisme des classes est très puissant. Au moment où nous créons une nouvelle classe, quatre méthodes sont automatiquement intégrées pour assurer un comportement minimum de la classe sans aucune écriture explicite. C'est ce qui s'appelle la « forme canonique d'une classe ».
Ces quatre méthodes sont :
Constructeur par défaut : le constructeur par défaut est un constructeur qui ne possède pas de paramètre et donc qui n'attend pas d'argument. Par défaut,ce constructeur ne fait rien. Si vous désirez avoir un comportement particulier, il sera nécessaire de le redéfinir. Toutefois, ce constructeur n'existe plus à partir du moment où vous définissez un nouveau constructeur qui possède un nombre quelconque d'arguments. Si vous désirez, malgré tout, posséder, en plus, un constructeur par défaut, il sera également nécessaire de le redéfinir.
Constructeur de copie : il est possible de créer un objet à partir d'un autre objet (bien entendu, de la même classe). Ce constructeur attend l'objet en paramètre et copie chacun de ces attributs pour les associés à ses propres attributs. Le comportement par défaut est donc une copie membre à membre.
Destructeur : de même qu'il existe une phase de construction, il existe systématiquement une phase de destruction. Ce mécanisme est utile lorsque nous avons besoin de gérer des variables dynamiques pour notamment leurs libérations.
Un destructeur se reconnaît parce qu'il porte le même nom que la classe précédé du tilde « ~ ».
Opérateur d’affectation : nous avons déjà utilisé cet opérateur lorsque que nous avons réalisé des affectations (des copies) de structures. Par défaut, comme pour le constructeur de copie, l'affectation propose une copie membre à membre. Ce comportement est très intéressant puisque nous n'avons pas besoin d'écrire quoi que se soit et c'est généralement ce que nous avons besoin. Il existe, malgré tout, des situations où ce comportement n'est pas souhaitable. Dans ce cas là, il sera nécessaire de redéfinir cet opérateur.
Petite illustration :
 |
e) Peut - on définir plusieurs constructeurs ?
On peut en C++ définir plusieurs constructeurs. Grâce à la surdéfinition, il serait souhaitable de répondre à l'attente des utilisateurs, en proposant d'autres constructeurs, pour répondre à tous les cas de figure, c'est-à-dire :
1. Pouvoir construire un nombre complexe sans préciser de valeurs initiales. Cela consiste à définir un constructeur par défaut. Ce nombre complexe doit représenter le point origine.
2. Pouvoir construire, tout simplement un nombre réel, puisque les réels sont compris dans l'ensemble de définition des nombres complexes. Ce constructeur prendra un seul argument. La partie imaginaire doit être nulle.
 |
f) Constructeur avec des arguments par défauts.
Au lieu d'avoir trois constructeurs différents, nous pouvons utiliser les arguments par défaut, et du coup, définir un seul constructeur qui traitera tous les cas de figure désirés.
g) Quelle est l’importance du constructeur par défaut ?
Quoi qu'il arrive, la création d'un objet doit toujours passer par une construction. C'est d'ailleurs pour cela qu'un constructeur par défaut existe, même si le programmeur n'en fabrique pas.
Revenons sur les tableaux d'objets. Deux cas peuvent se présenter. Soit nous devons déclarer un tableau d'objet sans initialisation explicite. A ce moment là, c'est le constructeur par défaut qui est sollicité pour construire chacun des objets en particulier. Si vous désirez effectuer une initialisation explicite, il suffit d'utiliser la syntaxe classique, c'est-à-dire, en utilisant les accolades, et de préciser pour chacun des objets, le constructeur adapté.
Souvenez-vous qu'il n'est pas possible d'initialiser explicitement chacune des cases d'un tableau dynamique. C'est bien sûr également vrai pour les tableaux d'objet, d'où l'importance d'avoir un constructeur par défaut.
h) Peut – on concevoir des objets constants ?
Le principe même d'un objet constant, c'est que ces attributs demeurent inchangés pendant toute sa durée de vie.
Le principe de protection impose par défaut qu'un objet constant ne puisse utiliser aucune des méthodes, puisque l'une d'entre elle peut éventuellement proposer un changement d'état à l'objet, c'est-à-dire, modifier ses attributs.
Toutefois, il existe des méthodes qui ont un rôle uniquement consultatif, qui donc, par essence, ne change pas l'état de l'objet. Il serait intéressant que ces méthodes puissent être utilisées par ces objets constants. C'est notamment le cas pour la classe complexe qui utilisent deux méthodes consultatives ‘module ' et ‘ argument '.
Lorsque vous décidez qu'un objet constant puisse utiliser certaines méthodes, ces dernières doivent être qualifiées de constantes. Les autres méthodes de la classe ne pourront donc pas être utilisées. Pour les objets qui ont le statut de variable (c'est-à-dire, non constant), ils pourront utiliser indifféremment les méthodes classiques et les méthodes constantes. Pour qu'une méthode devienne constante, il suffit de placer le suffixe « const » après sa signature.
Attention : Une méthode constante ne doit en aucun cas modifier un des attributs sinon le compilateur donnerait une erreur de compilation, ce qui va, bien entendu, dans le sens de nos propos.
POINTEUR THIS
a) Quel est le rôle propre a ce pointeur ?
Ce qui est très sympathique dans la programmation des objets, c'est que les méthodes de la classe accèdent directement aux attributs de l'objet sans spécifications supplémentaires.
Malgré tout, la question se pose de savoir comment fait la méthode pour arriver à se connecter sur les attributs de l'objet désiré. En effet, chaque objet de la classe possède sa propre copie des attributs, afin que chacun puisse avoir sa propre identité pour que leur état puisse évoluer de façon différente.
Par contre, le comportement demeure identique pour tous les objets de la classe. En effet, il n'existe qu'une seule copie de chaque méthode. Chaque méthode doit donc fonctionner pour tous les objets de la classe.
Le terme « this » désigne un pointeur vers l’objet « courant » à l’intérieur d’une fonction membre. Il est utilisé lorsque aucun autre nom d’objet n’a été spécifié. De plus, dans une fonction membre normal, « this » est le premier argument implicite de la fonction.
Dans les faits, le compilateur propose deux transformations pour incorporer ce pointeur afin de résoudre la connexion entre la méthode et les objets associés, à savoir :
D'abord, traduire la méthode pour q'elle possède un paramètre supplémentaire - le pointeur « this ».
Ensuite, traduire chaque appel de la méthode pour ajouter un argument supplémentaire – l'adresse de l'objet pour lequel la méthode est invoquée.
 |
Tout ce que nous venons de voir se fait implicitement, et généralement, nous n'avons pas besoin de faire référence au pointeur « this ». Toutefois, il existe des situations où son utilisation directe peut s'avérer intéressante.
b) Comment peut – on définir une fonction membre ?
Une fonction membre peut être définie dans une classe ou à part. Lorsqu’une définition de classe est définie dans la classe, elle ressemble à celle de fichier *.h.
La directive #include insère le contenu lors du processus de compilation. Le compilateur C++ « voit » votre code comme si le fichier inclus *.h en faisant partie intégrante.
Une fonction membre peut être définie en dehors de la classe est dite « outline ». Ce terme s’oppose à la notion de fonction intégrée, « inline », définie à l’intérieur de la classe.
Les fonctions membres peuvent être surchargées de la même manière que les fonctions conventionnelles.
c) Est-ce possible d’avoir les paramètres des méthodes qui ont le même noms ?
Il est souvent très difficile de faire un choix judicieux quant au nom d'un paramètre.
De plus, à l'heure actuelle, la plupart des environnements de développement intégré proposent des systèmes d'aides automatiques qui, dès que vous tapez le
nom de la méthode, l'ensemble des paramètres attendus apparaissent avec leur type et leur nom.
Dans ce cas là, il est judicieux de proposer des noms évocateurs pour que l'utilisateur sache ce que la méthode attend comme arguments.
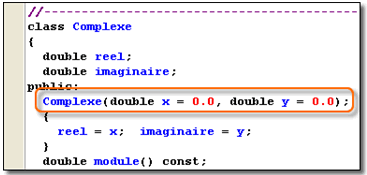 |
En reprenant l'exemple du nombre complexe, j'avais d'abord choisi comme paramètres du constructeurs, respectivement, les noms x et y. Bien que nous comprenions à quoi cela correspond, cela reste imprécis.
En effet, à la construction, le tout c'est de savoir si l'objet à besoin d'une partie réelle et d'une partie imaginaire. Il devient plus judicieux d'employer directement ces noms là. Du coup, la question qui vient immédiatement à l'esprit, c'est :
Est-ce qu'il ne va pas y avoir un conflit entre le nom du paramètre et son attribut équivalent ? La réponse est « non », chacun est dans une portée différente :
1. Pour le paramètre la portée, c'est la méthode,
2. Pour l'attribut, la portée, c'est la classe.
La difficulté, toutefois, c'est de pouvoir atteindre l'attribut. C'est à ce moment là que nous avons besoin de l'opérateur « this » puisque que c'est justementson rôle.
 |
Lorsque nous faisons référence à un identificateur, c'est toujours la variable dont la portée est la plus locale qui est prise en compte. Lorsque nous évoquons ‘ imaginaire ', c'est donc une référence au paramètre de la méthode puisque sa portée est plus immédiate que la portée de la classe.
d) Est il possible d’appeler plusieurs méthodes simultanément ?
Imaginons une classe « Notes » qui permet de gérer un ensemble de notes d'élèves, pour qu'à la suite, il soit possible de calculer : la moyenne, la note la plus haute, etc.
Cette classe est composée d'un tableau de notes ainsi qu'un autre attribut qui gère à chaque instant, le nombre de notes déjà introduites.
C'est la méthode « ajout » qui s'occupe d'insérer les notes successivement. Voici un scénario possible :
 |  |
Ce qui serait agréable, ce serait d'appeler plusieurs fois cette méthode «ajout », mais cette fois-ci, sur une seule ligne.
 |  |
Attention : pour écrire de nouveau « ajout » après le séparateur « . », il est nécessaire d'avoir à gauche du séparateur, le type correspondant, c'est-à-dire, la classe « Notes », puisque cette méthode « ajout » n'existe que par rapport à cette classe.
Il faut donc que cette méthode renvoie une référence vers sa propre classe (une référence permet de se connecter sans faire de copie).
Finalement, dans la méthode « ajout », il faut employer un return et renvoyer l'objet dans lequel nous sommes. L'opérateur « this » est justement un pointeur vers l'objet sur lequel nous travaillons. Il est nécessaire de le déréférencer pour que l'on passe l'objet et non pas l'adresse de l'objet.
e) Quelles sont les étapes importantes à savoir, Maintenant ?
1. Etablissement de l’espace mémoire sur la pile.
2. Vérification de la donnée (si constructeur correct ou pas).
3. PILE = Durée de vie de la fonction.
DESTRUCTION D’OBJET
La construction (vu au chapitre XVII) permet de personnaliser des objets est très fréquemment alors que la destruction l'est beaucoup moins. Nous verrons, malgré tout, des cas où il est absolument nécessaire de redéfinir le destructeur proposé par défaut.
a) Qu’est ce qu’un destructeur ?
Une fonction « destructeur » à pour caractéristique :
c'est-à-dire :
- Porté le nom de la classe, précédé de ~.
- Ne retourne rien.
- Est exécute automatiquement lors de la destruction de la variable
-> À la fin du programme dans le cas d’une variable globale ou statique,
-> En quittant la fonction dans le cas d’une variable automatique.
Le destructeur fait usage du mot réserve « this.this » est un pointeur sur la variable qui est en train d’être traitée.
b) A quoi peut servir de mettre des destructeurs dans nos objets ?
b1) Comment se passe la destruction des objets ?
Reprenons la classe « Complexe » afin de visualiser à la fois, la création et la destruction de l'objet.
 |
Finalement, tout se passe correctement. L'objet se détruit automatiquement quand il le faut. Justement, il est assez fréquent d'avoir plutôt des objets locaux.
Toutefois, nous avons souvent aussi besoin d'objets dynamiques. Cette fois- ci, cela ne se fait plus automatiquement, c'est le programmeur qui décide quand l'objet doit être créé, à l'aide de l'opérateur « new », et quand il doit être détruit, cette fois-ci grâce à l'opérateur « delete ».
 |
Nous avons découvert qu'il existait un destructeur. Vu ce que nous venons de voir, à quoi peut-il bien servir, puisque qu'apparemment tout se passe correctement ?
Maintenant, ils nous restent une seule question à ce poser.
c) Quel est le rôle d’un destructeur ?
Un objet qui à été créé peut être détruit : « tu es poussière et tu redeviendras poussières ». Si une classe peut avoir un constructeur qui créé des objets, elle devrait aussi avoir une fonction membre spéciale qui se charge de faire le ménage.
Notre regard doit se porter à l'intérieur de la classe.
Tout dépend de la déclaration des attributs, ou plutôt de la zone mémoire utilisée pour stocker leurs valeurs.
Si les valeurs des attributs se situent sur la pile ou dans la zone statique, nous venons de voir que tout se gère automatiquement. Il existe un cas où le programmeur doit s'occuper de la destruction, c'est lorsqu'au moins un attribut fait référence à un objet dynamique.
En effet, dans ce cas là, il sera nécessaire de libérer la variable dynamique avant que les attributs ne soient détruits automatiquement.
C'est donc là que le destructeur intervient.
ATTENTION : La séquence des destructeurs exécutés lorsqu’un objet est détruit est invoquée dans l’ordre inverse de l’appel des constructeurs correspondants.
d) Petite illustration du a) et b) :
Pour illustrer ces propos, reprenons l'exemple de la classe « Notes » en envisageant, cette fois-ci, que la taille du tableau est totalement variable. C'est au moment de la création de l'objet que l'on précise la dimension.
 |
AGREGATION & COMPOSITION
a) Introduction :
Un objet peut être constitué d'attributs de n'importe quel type. Du coup, il est possible qu'il soit lui même composé d'autres objets. Si je devait extrapolé ce que je viens de dire, c’est un peu comme les poupées russe qui s’emboîte les unes dans les autres. La plus grande englobe les plus petites.
C'est ce que nous appelons la composition ou l'agrégation par valeur.
L'étude qui suit va nous permettre de maîtriser la création complète de l'objet conteneur associé à ses objets membres. Pour aborder ces différents thèmes, nous allons nous servir de classes simplifiées, afin de comprendre rapidement les mécanismes mis en jeu.
ATTENTION : Ce n’est pas de l’agrégation par référence.
 |

Rq : Le conteneur doit s’occuper du contenu.
c) Création et utilisation des objets :
Est-ce qu’il nous faut un constructeur ????
c1) Aucune des classes ne possèdent de constructeur :
Nous allons contrôler le fonctionnement d’un objet durant toute sa vie :
création, utilisation, destruction.
Par rapport à ce contexte, nous allons développer plusieurs petits concepts ayant pour but de vous mettre sur la bonne piste, de bien comprendre ces termes techniques.
Maintenant passons aux choses plus importantes qui sont :
Î Création d’un objet « en béton »
Î Utilisation de cet objet.
Voici les étapes a ne pas oubliées :
Il faut allouer la mémoire nécessaire en rapport à la dimension des objets. Une fois l’emplacement mémoire constitué, chacun des objets internes, s’ils existent, doit être construits. Des que les objets internes sont définitivement construits, c’est
au tour du constructeur de la classe conteneur de prendre le relais afin de terminer la création des objets.
Les objets internes sont des attributs comme les autres. L’accessibilité ne se fait qu’au travers des méthodes de la classe englobante.
Les méthodes des objets internes ne seront donc utilisées que par des les méthodes de la classe conteneur.
Par exemple, pour déplacer un cercle, il nous suffit simplement de déplacer le centre de ce même cercle.
Nous pouvons maintenant s’apercevoir du rôle très importants du conteneur par rapport aux objets internes. C’est lui qui doit s’occuper de tout. Il est normal procéder de cette façon, puisque les objets intègres sont utilisés de façon particulière par rapport à leur conteneur.
c2) Les deux classes redéfinissent les constructeurs par défaut :
Finalement, tout fonctionne très bien sans avoir écrit beaucoup de lignes. Ce qui est embêtant, tout de même, c'est que l'état de tous ces objets est totalement aléatoire. Il serait peut être plus judicieux d'imposer un état par défaut, en proposant, par exemple, une valeur nulle à chacun des attributs.
On pourrait se demander pourquoi le système ne le fait pas automatiquement. Il ne faut pas oublier que ce langage a été conçu pour être le plus performant possible en terme de rapidité au détriment de la validité des valeurs. Du coup, le système ne va pas perdre son temps à placer des valeurs sur la pile, surtout, qu'il est préférable que se soit le programmeur qui fasse son choix.
Règle : Lorsqu'un objet interne possède un ou plusieurs constructeurs mais pas de constructeur par défaut, il est impératif que la classe conteneur définisse au moins un constructeur. Ce ou ces constructeurs doivent absolument faire appel explicitement a un des constructeurs de l'objet interne. Il faut, tout simplement, être sûr que l'objet interne soit correctement créé.
d) Qu’est ce qu’une liste d’initialisation :
Il existe une syntaxe appropriée pour les appels explicites. C’est une liste d’initialisation des membres qui suit la signature du constructeur et qui débute par un deux points « : ». Le noms du membre est spécifié, suivi par les valeurs initiales entre parenthèse.
Si vous possédez plusieurs objets membres, chacun devra être initialise et donc faire parti de la liste d’initialisation. La séparation entre les différents objets s’effectue à l’aide de l’opérateur virgule « , ».
ATTENTION : L’ordre d’initialisation des objets n’est pas du tout impose par l’ordre de la liste d’initialisation mais uniquement par celui de la déclaration des membres de la classe.
En toute rigueur, toutes les instructions qui se situent dans le corps du constructeur sont des instructions de calcul plutôt qu’une initialisation proprement dite.
En effet, n’oubliez pas que les types dits primitifs, sont finalement considères comme des classes et que pour eux, les constructeurs existent également :
Î Les types primitifs ont un constructeur par défaut qui, soit ne fait rien, soit propose une valeur nulle pour les variables statiques.
Î Les types primitifs possèdent également un constructeur avec un seul argument dont le type de paramètre correspond au type de la variable.
Souvenez vous bien, la zone de mémoire statique est très particulière car la valeur des cases mémoire n’est jamais aléatoire, il doit toujours exister une valeur précise.
Rq : Si aucune valeur n’est proposée, la case mémoire prend alors une valeur nulle. Cependant, nous utilisons le constructeur par défaut, car généralement, ils ne font rien.
e) Initialisation particulières :
Nous pouvons avoir besoin d’attributs particuliers comme des attributs constants ou alors des attributs qui fassent référence à d’autres éléments extérieurs. La déclaration de ces attributs particuliers reste classique, toutefois, il est impératif que ces éléments soient toujours initialisés avant leurs utilisations.
En effet, lorsque vous êtes à l'intérieur du constructeur, la phase d'initialisation proprement dite est terminée et vous effectuez une affectation sur un élément constant, ce qui est totalement interdit.
Encore une fois, la liste d'initialisation, comme son nom l'indique, permet de palier à ce problème. C'est effectivement au moment de l'initialisation qu'il faut préciser la valeur de la constante et pas plus tard.
Finalement, dans le cas d'un attribut primitif non constant, nous avons le choix entre la liste d'initialisation ou l'affectation directe pour imposer une valeur.
Dans le cas où cet attribut est constant, il n'y a pas d'alternative, le seul choix possible est l'initialisation explicite.
Le procédé reste le même si vous devez implémenter des attributs de type
« référence ». En effet, toute référence doit être également initialisée avant son utilisation.
f) Que fait le programme, quand il y a plusieurs constructeurs dans la classe ?
1°) Regarde si il y a un objet dans la classe.
2°) Se rapport à l’autre classe.
3°) Return dans le « main » au départ pour l’exécution.
Je remercie M. Remy Emmanuel, pour m' avoir donner l' autorisation de reprendre son cour, de le simplifier et de le publier sur l' Internet, plus particulièrement sur mon site.
Aucun commentaire:
Enregistrer un commentaire
commenatires